How to win a Data Science challenge in Kaggle?
Introduction
The main topic of this article is about winning or at least landing a descent top rank in a Data Science competition in Kaggle. It’s been written mainly for the general audience. Now everyone is talking about Data Science, AI, and Machine Learning and how the future of the world depends on the technologies associated with these hot topics. Within this context, Kaggle is THE PLACE for Data Science enthusiasts.
What is Kaggle?
“Kaggle, a subsidiary of Google LLC, is an online community of data scientists and machine learning practitioners. Kaggle allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges.” — Wikipedia
The boldest feature of Kaggle is that currently, it is the de-facto place where Data Science competitions are held there. For instance, many big companies, such as Microsoft, Google, and Facebook, had had various competitions in Kaggle for different reasons. The reason to post a challenge could range from the getting publicity, recruiting talented people, exploiting cheap labour, and least but not last to gather new insights about the ways they (companies) could tackle their data-driven problems.
Kaggle is not a new thing — but it could have managed to get a lot of attention over time!

Why you may be interested to enter a Kaggle competition?
For most people, there could also be a various good reason to compete in a Kaggle competition, including:
● Trying to learn the skills for Data Science and get experience. Working on a real-world Data Science problem is hard, some people believe that you must spend at least 10k hours on something to be a professional in it
● Build a profile for your career. Having a Kaggle profile can be a good thing in your resume if you want to get a job related to Data Science
● For the money. Most Kaggle challenges do not provide much as the monetary prize for the top winning teams, but still, there are few high-profile challenges, with million-dollar range prize. The motivation behind the challenges with the money and without the money is a psychological thing. The amount of money in the award is not essential, but it helps gather many people from lower-income strata — making more people joining the challenge
● For the thrill of the competition, and the coolness factor involved. For many people, it could be fun to compete with others, it is like playing an online video game like WoW, or Fortnite somehow — an entertaining activity. Also, competing in Kaggle has a certain aura of coolness around it; years ago, at the start of the current millennium, it has become apparent that the future of the computing is to scale up computers, it leads to new technologies and trends. Cluster Computing (CC) was and is one of the critical factors back then, you could find a description like these in justification why people were so excited about CC at that time:
o “Coolness Factor: There is just something really cool about playing with clusters. Although a purely subjective factor, it nonetheless has driven much activity, especially among younger practitioners who react to many of the empowerment issues above but also to the attraction of open source software, unbounded performance opportunities, the sand box mindset that enables self-motivated experimentation, and a subtle attribute of the pieces of a cluster “talking” to each other on a cooperative basis to make something happen together. There is also a strong sense of community among contributors in the field, a basis for a sense of association that appeals to many people. Working with commodity clusters is fun!” — Encyclopedia of parallel computing, Springer
We could — by replacing the word related to cluster computing (i.e., boldened terms) with the right words (i.e., Data Science, ML, and AI) — use almost all those enticing things about Data Science, AI, and ML.
The central assumption here is that the audience (YOU!) know enough algorithm, and programming to be able to use Kaggle. The other important assumption that I’m making is that people learn best by doing! This writing does not try to teach you how to do these — be able to code; be able to understand and implement algorithms; read and analyse other people’s models — to you.
Choose your challenge wisely
The main starting point for entering a challenge in Kaggle is to pick up a challenge that firstly interests you — and secondly, you have the skills and resources to handle that challenge. One way to categorise the challenges in Kaggle is based on the format and shape of the data which is going to be used for the competition. In general, you could classify the competitions based on this method into two types. First are the challenges with tabular data, where the data is represented in tables with columns and rows in a natural way. The second type is the challenges that the data is not innately served or represented as rows of records packed up into tabular file formats such as CSV or MS Excel. The main differences between these two types of challenges are shown in the table below:
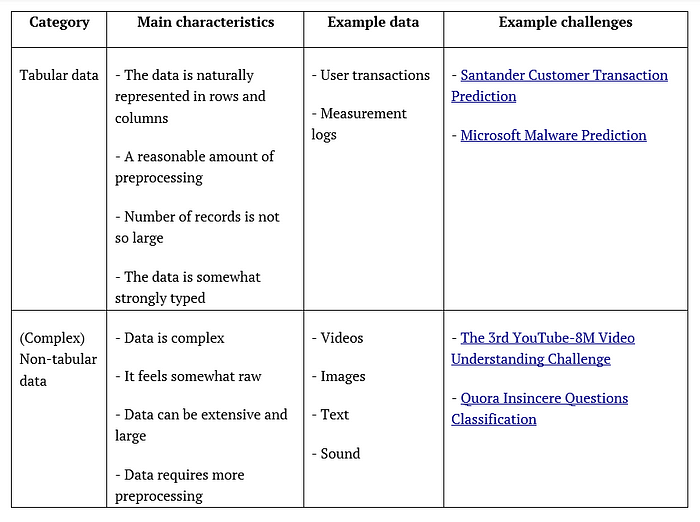
This categorisation is not totally accurate because there are many competitions where their data can be a mixture of tabular and non-tabular data; let’s assume for the sake of simplicity we keep our simple classification throughout this text :-).
Generally, the type of the data of a challenge you chose determines the skills you need to have to win that challenge — or at least be at the top of the leaderboard.
Learn the skills you need
The minimum requirement to start working in a Kaggle competition is to be able to develop the code to submit a prediction. In many cases, people don’t start from scratch; instead, they try to use others’ code written in Python or R to start. Nevertheless, to be able to do anything serious in Kaggle, you need to have many more skills under your belt. These skills can be summarised in the following lines:
- Good understanding of software development process, and related tools
- Good knowledge of the primary machine learning and data mining algorithms
- An analytical mind
- Enough knowledge of linear algebra, optimisation, and statistics
- Enough knowledge of data processing and management tools and technologies
The following picture an incomplete list of many relevant terms associated with the aforementioned required skills:

Find teammates
One important thing that could help you a lot while you are in a Kaggle competition is to find other people and teaming up with them. The type of people you should look for usually have got to have two characteristics, firstly they should be better than you in some way, so you can hope to learn and improve yourself via interacting with them, possibly via osmosis. Secondly, they preferably should be thinking differently than you, many people are sharing many similarities when they approach a problem, but for a predictive ML challenge, people with a congruent way of thinking are not going to be useful!

Employ an agile workflow
The simple idea behind a building a predictive model is that there exists a collection of functions that accept some input variables and are going give a good enough approximation about the labels or target variables in the dataset. During the lifespan of a challenge, you need to be able to absorb new ideas add them into your models. It could include reading other people’s codes, comments, replies and posts to find and collect useful information about their approaches. Usually, the hard part is not to find helpful information from other people’s work and models — but it is to somehow add their ideas into your workflow. The problem is that usually as you start into a challenge — you start with a simple model — over time your model is going to become more and more complex, so there is impending problem that may at some point of the challenge your model fall into local minima or maxima for the score function used in the challenge.
You should automate as much as possible, every time you build and train a model, you can notice that parts of your work are going to be repeated. If your workflow contains many repetitious subtasks, there is an excellent chance that you could exploit it to save your precious time. Subtasks such as data reprocessing (e.g., imputing the missing values), Explanatory Data Analysis (EDA), and feature engineering are good candidates for automation.
It is an interesting challenge in itself— how to set up an efficient, agile Data Science workflow!
Understand the challenge description
Read the challenge description very carefully, then answer the following questions:
- Do you understand what the type of challenge is? Is it a classification, regression or ranking challenge?
- What is the score, or error function used in the challenge? Why they picked this particular function?
- Does the challenge require you to have the right amount of domain expertise?
- How large are the train and test datasets?
- How raw is the data? How much time do you think it will take to build a starter model?
- Does the challenge need you have access to a particular type of resource?
- Is it a kernel challenge? What limitations are in place?
- How long is the life span of the challenge? How much time can you invest in it?
- Are there any previous challenges like this one you intend to take on? If yes, what can you scavenge or reuse from the previous similar challenges?
The point of answering these questions is to take on a challenge with a proper contextual understanding. If building a model, for example, requires a lot of computational resources (i.e., GPUs or TPUs) or a specific domain knowledge about the data is a critical advantage, and you do not have access to neither of these, you could head into the challenge hoping for getting a good standing on the final private leader board — only to disappoint yourself at the end.
Do not skip Exploratory Data Analysis
Exploratory Data Analysis is a very essential activity in every Data Science process. It is not something that you could learn by reading books — it is much like an art than an industrial process. But you should take it very seriously when you start a challenge in Kaggle. A typical EDA pipeline may encompass — but not limited — to the following relevant subtasks:
- Using univariate and multivariate data analysis techniques
- Data visualisation — it may include dimensionality reduction steps
- Statistical hypothesis testing
- Taking summary statistics from the data
- Using clustering, anomaly detection/outlier detection, novelty detection techniques
EDA can be very time consuming, especially when the size of the dataset is large or the dataset is quite raw (i.e., it needs to be preprocessed a lot first). The main idea is that make the data talk to you! There are people in Kaggle that prepare great EDA kernels, you can learn from their work.
Start off with a robust validation
Always start with the construction of a high-quality validation for your model as early as possible. The main point of this work is that before anything, you should make sure that you are not going to overfit (or underfit) on your validation or test data. Ideally, when you have your validation strategy readied you should get more or less the same score on Competition’s leaderboard as you get on your validation. It is easier said than done, though. When you have an excellent validation the rest of your efforts is mainly focused on three things — finding or building the best features, finding the best single model or ensemble, and finally tuning your model’s hyper-parameters!
Wining is hard so prepare to lose, but hope to win
To be able to win a Kaggle competition, you need to fight with many other smart and hardworking people from all over the world. To get a gold medal usually, you have to occupy one of the top 10 to 15 places in the final leaderboard, to get a silver medal you have to be within top 5% and to get a bronze to be no further than the top 10%. It is apparent that winning — i.e., to be in the first place — is not going to be easy, because many people you try to beat may have unique advantages compared to you. Winning a Kaggle challenge depends on many factors, including but not limited to having a good understanding of the domain knowledge for the data, possibly having access to high-end computational resources that gives an advantage throughout a competition, having a good grasp of the cutting edge algorithms in the area, and finally be lucky!
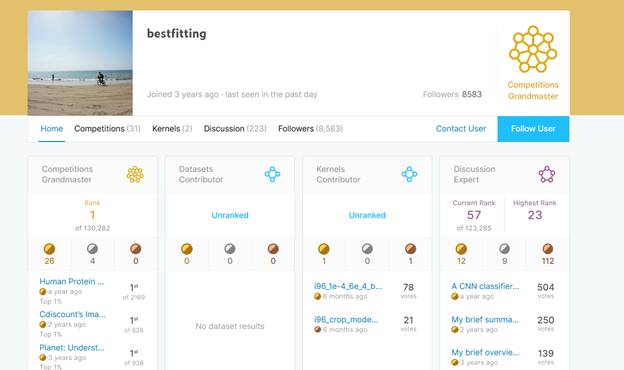
One good strategy could be to focus on a niche. In other words, try to compete in specific challenges which you have some kind of the upper hand. For instance, the current number one Kaggle, bestfitting, is almost totally focused on challenges where the data is an image dataset. One distinguishing feature of his approach is that he heavily uses Deep Neural Networks in his work.
Conclusion
It may seem obvious to you that winning or getting a medal in a Kaggle competition is not an easy task at all. You are right; winning is hard, mainly because it requires a mixture of proper amounts of work, knowledge, experience, and very importantly, a little bit of luck! But with investing the right amount of time and effort and having the lady luck on your side, it is not impossible to achieve.

